COMP704-Development-Journal
COMP704 - Development Journal for AI ML module
Project maintained by Ashley-Sands Hosted on GitHub Pages — Theme by mattgraham
Getting to know some basic Machain Learning AI frameworks
Entry: , Published:
| Return to index |
To begin, getting know some of the AI frameworks available in Python, we were given some tutorials using some of the example datasets available in scikit-learn [1]. Most notably the classic iris dataset. Furthermore, this demonstrated splitting the data in to a training and test set necessary for testing the fitness of the model once training is complete, which in turn encouraged us to underfitting/overfitting [2] our ML models. Lastly it taught me about displaying the data in different plots using matplot Python Library [3], which can be used to help understand the classification of the images [Fig. 1, Fig. 2] and recognize underfitting and overfitting. To be honest this was relatively straight forwards to follow along with and we swiftly moved onto Open Ai Gym [4] and stable_baseline3 [5]
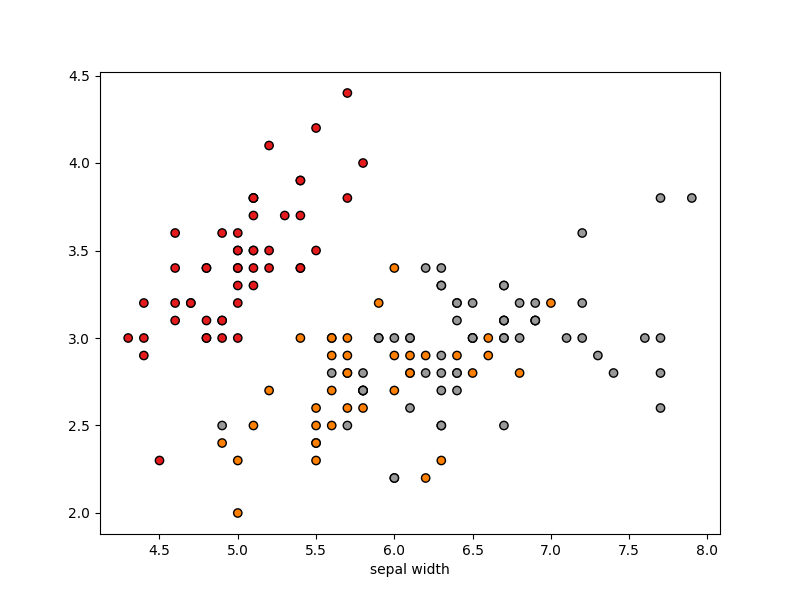
[Fig. 1. 2D plot of the iris dataset, showing the separation between the three different classification groups. which is not very cleat for two of the group]
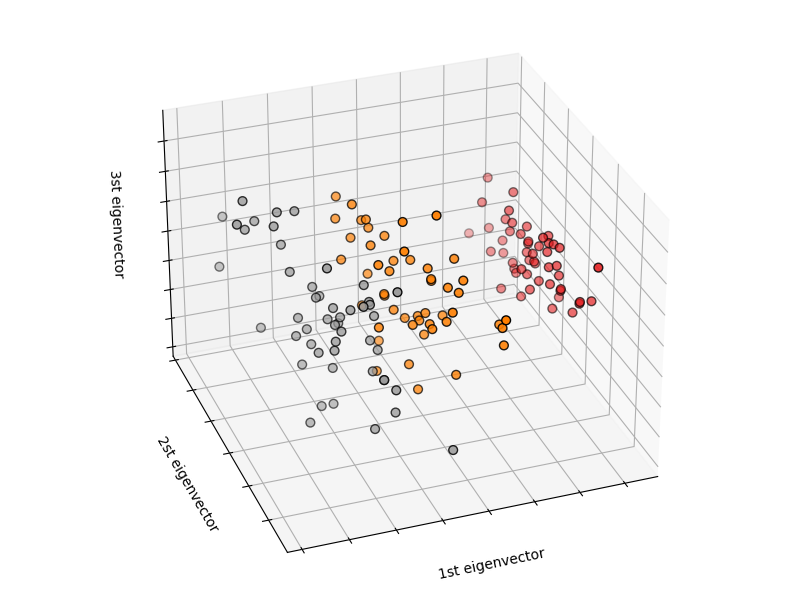
[Fig. 2. 3D plot of the iris dataset, making it much clearer to see the separation between the three classification groups]
OpenAi Gym is a framework (or toolkit) for developing and comparing reinforcement learning algorithms [4], while stable baseline 3 contains the algorithms themself. We were given another tutorial which outlined the basic steps required to start experimenting with the example games included in OpenAi Gym, namly cartpole. In the the tutorial we were encouraged to experiment with a couple of different models such as Deep Q Network (DQN) [5] and Proximal Policy Optimization (PPO) [6]. However, while it was nice to see it work, I was struggling to wrap my head around the structure of the application, mostly in regards to selecting actions, applying rewards and the training process. After a short conversation with my lecturer and digging through a couple of git repositories, I soon realised my misunderstanding. Basically, I didn’t realise that OpenGame AI is more or less just a framework for ticking (running) the environment and agents with the required methods implemented to train and run the Machine Learning model. Such as reset to reset the environment to it initialised state and the step method which ticks the environment and returns the latest observation, reward for the last performed action, whether or not we have completed the environment and some debug info.
We then pass the OpenAi Environment into the ML model which then uses the information returned from step to update the model and once it is done reset is called. Once training is complete it is as simple as ticking the environment, collecting the observations and passing it into the predict method available on the ML Model (ie, DQN, PPO, A2C …). The predict method then returns the action that the agent should perform and the next predicted state of the environment. And just like that we have an agent that’s able to play cartpole [Fig. 3]. :P

[Fig. 3. Show cartpole being played by an agent that was trained using Deep Q Netwrok after 100,000 training steps]
Cites
All citations are available in a single
[1] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in Python,” Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011.
[2] AWS, “Model Fit: Underfitting vs. Overfitting,” [Online]. Available: https://docs.aws.amazon.com/machine-learning/latest/dg/model-fit-underfitting-vs-overfitting. html, [Accessed 1 February 2022].
[3] J. D. Hunter, “Matplotlib: A 2d graphics environment,” Computing in Science & Engineering, vol. 9, no. 3, pp. 90–95, 2007.
[4] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba, “Openai gym,” arXiv preprint arXiv:1606.01540, 2016.
[5] H. van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double q-learning,” 2015.
[6] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” 2017
| Return to index |